Finding the optimal strategy for 2048 using Machine Learning
By letting python take control of the keyboard and mouse one can let the computer learn how to play the game 2048 without hard-coding the intricacies of the game itself.

Possible state of 2048 Game
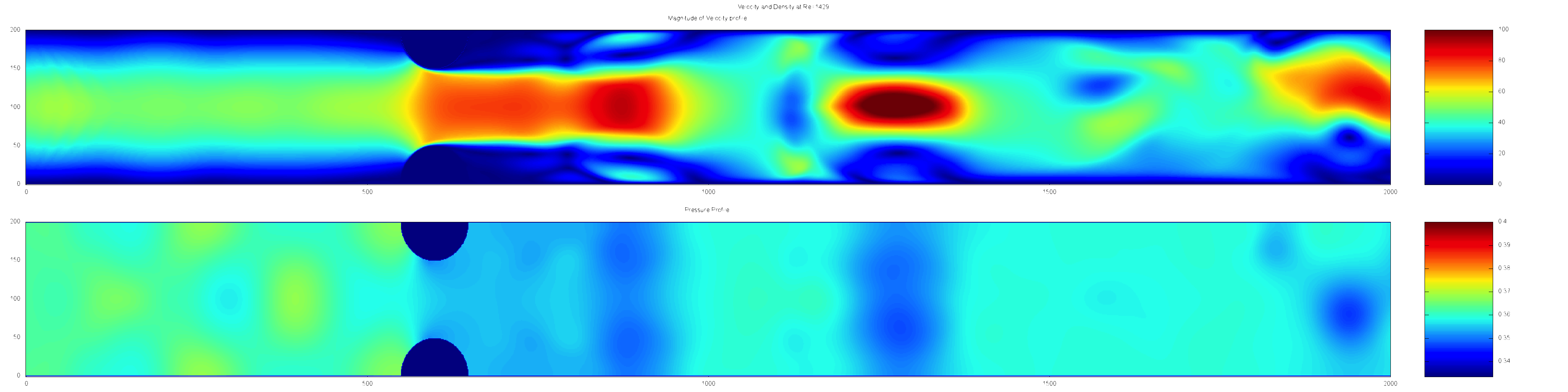
Using the Python packages pyautogui and PIL we investigate the game play of 2048. Gameplay is actuated by pressing one of the arrow keys which shifts the cells seen in Figure 1 in the given direction. An example of the procedure is seen below, the corresponding moves are Down, Left and Down again.


Matrix Form of board
We extract the numbers by finding the pixel color of each square. The ideal strategy of game play can be easily summarized into a Weight matrix. This weight matrix gives us the locations on the board where higher numbers should be as to maximize the long term reward. Throughout my research I found that almost every implementation hoping to beat the game uses some sort of weight matrix to place larger numbers into corresponding patterns, when possible that is.
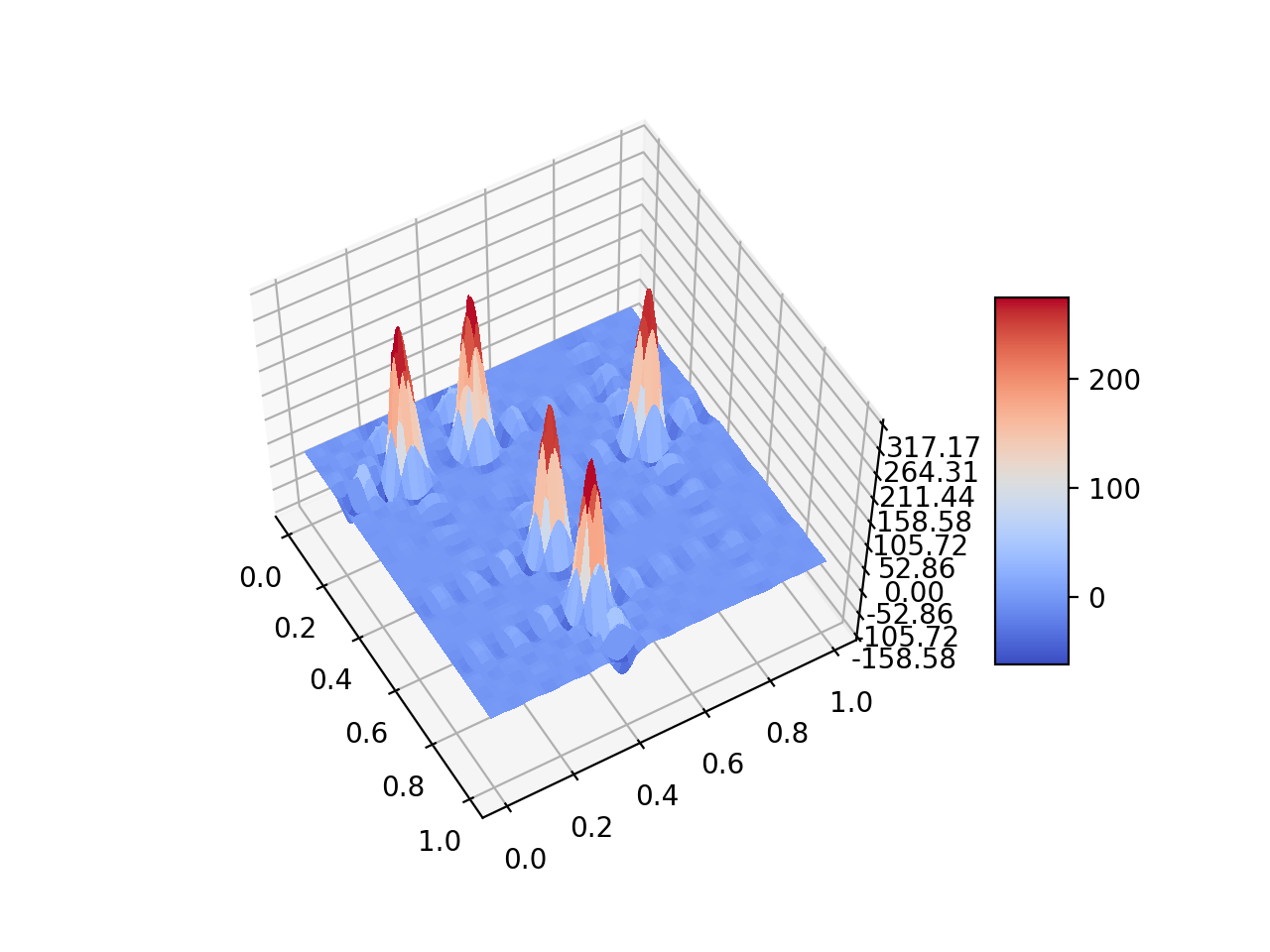
After playing the game a few times one may notice that we prefer the largest number to be located in a corner, but what of the second largest and the third largest? The interesting result is that the weight matrix is not symmetric. An example of a weight matrix found by Yiyuan Lee is seen below.

Notice how the largest weight is found in the top right corner with progressively smaller weights found along columns. Instead of working with the entirely of the state space of 2048 we limit our algorithm to the first 13 moves. This allows us to compute the Q-Values with respect to the next state by setting our state to be the move number. This gives us a Q-Value matrix of 13 by 4 due to the four possible actions. After some mathematical manipulations and many, many hours of my computer playing the game we can also recover a weight matrix.

The process described above maintains the total sum of the weights at 1, as such the result is slightly different from the weight matrix given above. But the geometric relationship of the weights is recovered. Also considering the symmerty of the system. This asymmetric and non-intuitive result is what we interpret as the optimal strategy of the game 2048. A more detailed description with a bit more math can be found at 2048 Q-Learning